Output from an agent that downloaded and cross-referenced a users resume against their github
Devpost link
Background
This was a Hackathon project for BoilerMake XII. A few friends and I were tired of some people
grifting (lying) on their resumes and cheating on technical OAs. I worked on the grift detection -
parsing a candidates resume, cloning all of their public githubs, examining commits, timestamps,
and annotating the resume.
Inspiration
We're students that have had to deal first hand with both the absolute travesty that is CS recruiting in the year two thousand and twenty five, and, on the other side, having to select from hundreds of applicants for technical student organizations.
There are a couple fundamental issues (some emergent!) with recruiting right now from both sides. From a job seeker perspective, interviews typically involve absurdly difficult leetcode problems that are not that tied to engineering on the job - it's incredibly difficult to stand out, when the hoops to jump through are the same for everyone, leading to a forced strategy of mass applications to increase odds of finding employment.
From a recruiter perspective, students lying about their technical qualifications is very common (we've dealt with it with students that reallllllyyy wanting to get into a club). Additionally, classic engineering assessments are becoming increasingly irrelevant as LLMs master competitive programming (e.g. t10 code forces) and a new assessment is needed; however companies and organizations are still looking for assessments that save them time / effort - low human capital requirements for our product. Companies don't give hard leetcode questions because they necessarily want to, but because they're a great filter.
This leads to a negative experience where students are sending out tons of applications and grinding a poor proxy to actual talent and recruiters are dealing with an inundation of poorly qualified applicants with no great, low-effort screening method.
What it does
Our platform combines fairly advanced resume analysis, and a job description to accomplish a number of useful insights. Resumes are cross referenced with Github accounts and AI-enabled "grift" detection is performed with highlighting and notes right on the resume -- all automatically with no recruiter work. If an applicant is select to interview for a role, custom questions are generated based on the information present both on the resume and the role. Furthermore all of Github is searched for relevant real world examples of engineering work to be presented to the applicant for their thoughts, fixes and analysis. This mirrors on the job performance more closely than thing like Leetcode.
How we built it
We begin by extracting all of the information from a resume, including the person’s github username and email username. This then allows us to cross check the person’s claims with their github projects. More specifically, we scrape all of the repos that a user has contributed too using beautiful soup, then sample the most important code samples based on entropy that are then fed to an LLM model as context. The model then matches each claimed project on a resume to a github project.
After we accomplish this, we interate through all projects, cloning the repos, and extracting the user contributions using git. Then we feed an LLM with the user commits, project description, and readme, allowing the LLM to judge the commit quality, commit data, and commit frequency to provide a legitimacy score. We repeat this for all projects.
After this step, we then annotate the PDF version of the resume, pointing out the strength of a user’s claim, whether the github exists and so on.
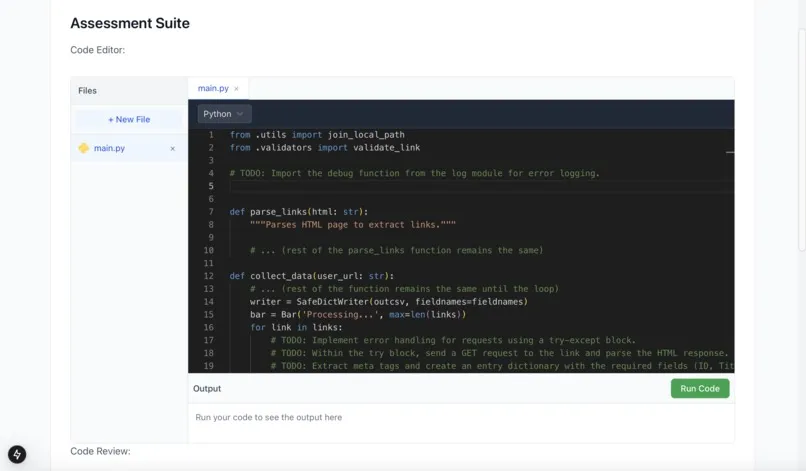
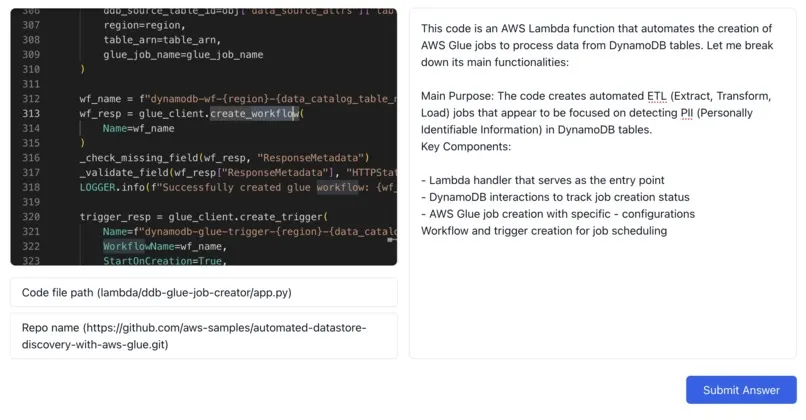
Because many LLMs are incredibly skilled at memorizing solutions, we wanted to test how a candidate would perform with tasks beyond memorize the solution to two-sum.
We do this by extracting the keywords from a job description, taking the intersection with the keywords of the user resume. We then scape github for code samples from real, popular repos, creating fill-in the blank and conceptual questions, that are tailored to the user’s experiences. For example, if a user is interviewing for a ML position, we consider fetching repos such as Google’s Tensorflow model garden or Huggingface transformers. Additionally we fetch PRs and issues online, asking the user to see if they can fill out the requests.
The frontend was build using NextJS, and tailwind CSS for styling. This allowed us to build reusable components and easy page navigation. We operated a fairly straightforward backend client relationship where the content that a user provided and content generated by our tool was passed between front and back with GET and POST requests via API routes.
Challenges we ran into
Analyzing and working with large amounts of data is inherently challenging (searching all of Github for relevant work? - doing a deep dive into a users commits across organizations and all of time?!) and diagramming our application's data flows out was difficult. We also ran into simpler issues like LLM token limits and API rate limits. Lastly, working on disparate parts of a project across 4 different members also led to its own challenges - integration hell!
Learn more here.